[Reader, a warning: this is a draft – it will be refined and updated to be submitted with annual review materials by October 1. It is also a very long document, but it must be long in order to quantify and narrativize the different kinds of digital scholarship added to The Stainforth Library of Women’s Writing this year and why it matters to the project. My hope is that by continuing to take the time to blog DH scholarship processes, I can help draw attention to the work involved and the disciplinary expertise that is the difference between DH scholarship and non-scholarly data editing or website management.]
What did we accomplish this year in The Stainforth Library of Women’s Writing https://stainforth.scu.edu? Academic year 2018-19 was our second year hosted by SCU and our first full year in our new WordPress platform that is so much easier to work with than Drupal. We were fortunate to have Danna D’Esopo (’20) as an editor again this year, thanks to an FSRAP grant. This year was less about moving content and cosmetics–we did all of that in ’17-18 when we moved from Drupal to WP and from CU-Boulder’s server to SCU. This year, because of our deep involvement in editing person records, cross references, and mapping, we shifted our focus to recovering the diversity of the women writers represented in Stainforth’s library catalog and collection.
Time
I worked at least five hours per week on The Stainforth Library of Women’s Writing DH project for the entire academic year, including during the summer. For many weeks, this is a low estimate. This does not include the time/labor I spent researching and writing argumentative narrative scholarship on the library for peer reviewed articles and a book project. Most weeks during the term, I work side-by-side with my RA at the circulation desk work station in the library for four hours per week editing data, project planning, enhancing our user interface, and documenting our processes. I also managed a $4,000 contract with a programmer. While this admittedly sounds like peanuts money-wise, I am proud of how I prioritized and managed this contract to produce many meaningful changes that would have been beyond my expertise limit to make in a timely fashion.
Publishing Person Records
Stainforth project editors have been creating and editing Person records for several years now with the goal of learning more about who is in the library Stainforth collected and how the names in his catalog relate to verifiable identities of authors, editors, translators, and more. There are around 3,700 names listed in the library catalog, including multiple spellings of the same name and different names for the same person. In sum, each name in Stainforth’s catalog should be linked to a Person record to bring these together, where the name then has a standardized format, an XML ID, and fields for first, middle, maiden, last names; role (author, co-author, editor, translator, etc.); gender (if known); other name and pseudonyms; birth and death years (if known); and nationality. For each person record, we also have fields that collect permalinks, with the most important being a person’s VIAF.org Name Authority record link, as well as links to an author portrait or image, Wikipedia page, and Oxford Dictionary of National Biography entry. The last field is for Notes that indicate what authoritative source outside of VIAF was used to verify a person’s identity, such as Orlando or J. R. de Jackson’s bibliography of Romantic women poets.
Between academic years 2018-19, Stainforth editors created or edited 320 person records (we have 1,066 Person records in total). Together, we edited or linked 203 Name records–names as Stainforth wrote them in his catalog–to the Person records we created. My role in this process is to edit Name and Person records, spot check other editors’ work and perform quality control, pose and answer challenging editorial questions requiring disciplinary expertise in bibliography and women’s writing, manage workflow, and update our editorial guidelines for Person and Name records as we learn new nuances in our data. Now that we have stopped creating new Person records (for this phase), we are preparing this portion of our data for peer review.
This year, for the first time, we released Person records and published them on our live site. Thus, I also coordinated the design of the published record and how it would manifest in our search results. Here is an example person record published for Felicia Hemans: https://stainforth.scu.edu/catalog/person/?id=4311.
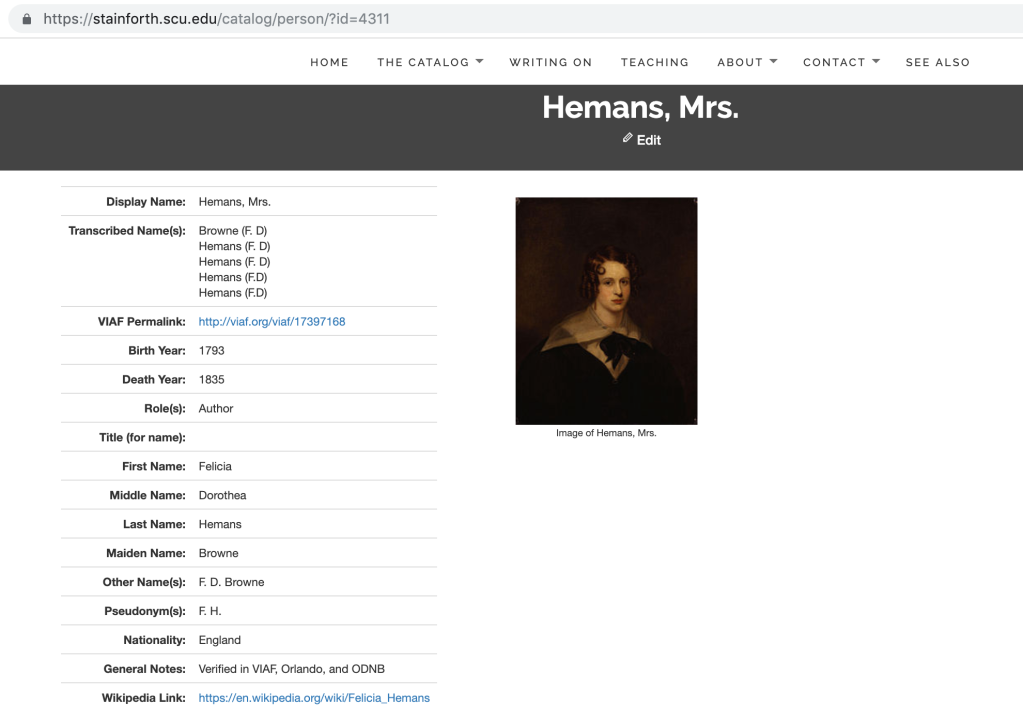
To arrive at this record, we debated what fields of Person data to publish, what data we collected to withhold, in what order the fields should appear, and how to get to the record from our search results. The most important fields are at the top: Display name (uniform name), what transcribed names in the catalog are linked to this Person record (we know there is a duplicate in this example and it is on our list to fix), and the VIAF record link. VIAF stands for Virtual International Authority File and aggregates the Name Authority records for authors across 40 major international libraries, like the Library of Congress. Providing access to the VIAF link for Hemans, for example https://viaf.org/viaf/17397168/, connects a user to her Person data across 21 international libraries and to entries for her titles in Worldcat, which link our Person record to copies of her books in libraries around the world and the search engine to locate those records. In other words, the VIAF link provides an Authority record for both Name and Title. Following names and VIAF link, we placed birth and death years next because they help identify an author, then role (author, editor, etc.), parts of the name and pseudonyms or other names, nationality (if known), notes on where this information is verified, and a Wikipedia link if one exists. To the right of all this information, we publish the image of the author if we have one. We decided to collect but not publish data on gender, TEI XML ID, image link, and the ODNB entry permalink. We may shift to sharing the ODNB permalinks–we hesitate to publish them at present because the ODNB is subscription based. The Gender field has been a source of important debate among our project team. We collect this data because it is important to track the men in the library versus the high numbers of women writers as well as those of nonbinary identity. It is fascinating that Stainforth did collect a few works by men, both as single author and co-authoring with women.
With the release of Person data came the job of figuring out how to query and display the data in relation to the rest of our data that the Search form yields. Due to limited funds for our programmer and my own limited knowledge of how to write algorithms for search queries, we reached a compromise that will need to be improved upon in future releases. Currently, our Search form allows searching under Names or under Titles but will not search the data in our Person records or output it on its own from our GUI, though we can run reports on this data directly from our database. When you search under Names, each result lists an author name as transcribed and the works attributed to that name in the catalog manuscript. We had to find a way to attach Person data to the names that each Person record links to. Chad’s and my solution was to place a clickable icon next to Name records that have an attached Person record. The icon appears next to each formally associated Name that appears in the Catalog. For example, the Person Record icon appears here next to results for a search on “Emma*” including “Bloodworth (Emma)” and “Goldie (Emma Mary)”.

However, we have collected usability feedback that relays that the gold icon appears vague to those who don’t know what it stands for. It is not a user’s first instinct to look for it and click on it to see Person data related to a name. Therefore, we are researching new icons and have added a message at the top search results showing the icon and indicating what it signifies in those results.
Search Enhancements
I want to emphasize how important enhancing the website’s Search capabilities is to this project: the recovery of women’s book history and the diversity of the women writers in this nearly lost activist library depend upon a user’s ability to search the catalog and find people, specific editions, book formats, or whatever it is they are looking for, reproduce searches, add filters, and understand their results. This Fall, I used $4,000 of my start-up funds to hire a private contractor who is a programmer for a short but very crucial task list. Here I add a special thank you to Chad Marks for his work – he always aims to make thoughtful contributions and enhancements to the project for project managers, editors, and end-users. One of the most important items on the list was to improve the Search form’s design, ease of use, and results for Names and Titles.

With Chad’s help, our search results received an incredible upgrade. Searching in the Title and Name forms used to produce results in different formats. Now, they are more uniform and provide catalog data on the left accompanied by an image of the catalog page featured on the right. At the bottom of the page, it lists the exact page#.line# for the result of the query and when clicked it opens up the page image for further inspection. This enhancement is important and well-designed because it recognizes the centrality of the manuscript to understanding individual search results. To understand what a specific author or title is to this library necessitates seeing that name or title on the manuscript page and considering its relationship to the other contents of the catalog.
I made 3 additional enhancements related to our Search functions:
- I added a link beneath the “Browse” page image of the catalog that has our transcriptions beside it to submit a transcription error directly to me.
- On the Search page, I added documentation that explains to a user how the Search algorithm works including how to “hack it,” find titles by anonymous authors (“by a Lady”), perform a keyword search on titles, and work around the fact that the form only searches Stainforth’s transcriptions (exactly how he wrote something in his catalog) for now. Bare-bones search forms might appear sexy and require less intellectual work to use, but ultimately they are black boxes that exchange transparency for “user friendliness.”
- On our Browse page, I added a second view of the manuscript that shows the full verso-recto page spread of the catalog pages in LUNA, provided open-access on the CU-Boulder Special Collections website. Previously, one could only see a single page image at a time because of the split view that showed the manuscript page image and the transcription in line beside it. However, this view leaves out critical information for a user. Stainforth used the recto and verso sides of his catalog differently consistently, and when we see the recto beside the verso we have the chance to see the order in which Stainforth acquired works and added them to his library catalog. Without the verso-recto view, it is much harder to see his collecting process.
While working on Person data, I discovered (or rediscovered), and verified with editors, that there are a few duplicates in our Names table. I sussed out a plan and procedure to fix these. Luckily, there are not too many and they do not have a substantial impact on search results.
Cross References
One of the many intriguing and highly political facets of Stainforth’s manuscript library catalog is the cross-references he includes, 667 to be exact. Stainforth uses his cross-references to make an argument about the importance of identity and connecting texts that respond to and critique one another. These entries in his catalog have to be handled differently than his bibliographical entries. Among the typical variations of cross references, we found: author maiden to author married name, author name to author name with a specific shelfmark, author name to a title (no shelfmark or special edition), author name to a title with specific shelfmark (a specific edition), title to title, and even some double cross-references where one author name leads to another, which is also a cross-reference that points to a third entry. Editors researched 667 cross references, designed editorial rules for how to assign the cross-reference link, and gave each cross-reference a pointer to a page and line number in the manuscript that best matches the interpreted intent of the cross-reference. I designed a TEI tagging schema for these entries that would encode the cross reference target in our XML and, therefore, would link related catalog entries in our Browse-the-Catalog view. We are still devising a plan for how to share cross-reference links in our Titles and Authors search results, since the x-refs must points to a page#.line#.
Publication Place Data Editing and Mapping
See the map of all of the publication places in the catalog here: http://stainforth.org/. Stainforth’s catalog provides a publication place as a city for 1,498 editions. While this is only about 20 percent of the number of editions in his library, it provides a snapshot that is nonetheless diverse and rich in data for analysis. The process of gathering and editing these data began in 2017 with the help of Allyson Long at Dartmouth College, and the plan for publishing these data in Leaflet was hatched with the help of James Adams, also at Dartmouth. This year, I continued editing cities, their lat/long locations, and associated bibliographical information to annotate mapmarkers with the goal of publishing a Leaflet map of the publication places for every title in the library that has a pub place in the catalog.

Process: We used hamstermap.com to batch translate the city addresses into geocodes and added additional metadata found in the catalog to each edition and address in an .xlsx file. (We ran a query from our MySQL daatabase to produce the starting Excel doc to which the lat/long etc. was added.) We then transformed the Excel doc into a geojson file, wrote a javascript file to call the data file and run it with a Leaflet marker package to output in HTML. Tony Pehanich (SCU) helped me edit my javascript and add buttons to the public map interface to show publication places by literary period or a custom date range (thank you, Tony!). The Leaflet package we used was selected specifically to output marker clusters that are labeled with numbers that count the number of markers in a cluster. This number changes as a user zooms in. Each individual marker shows the city name, author, title, pub year, publisher, printer, and page#.line# in the manuscript catalog. A notable flaw is that our lat/long locations are not yet specific to a particular publisher/printer’s address and instead group all editions published in a specific city together at the same address.
After making the Leaflet map, the process of making the map public was a surprisingly time consuming feat in and of itself. I kept thinking: why is this so hard? I desperately wanted to publish this map within WordPress on our project site. While there is a Leaflet app in WP, I learned after much troubleshooting that it was darn near impossible to embed the javascript files for my map in WP within our project. If it is possible, please let me know and I will cite you and send you dark chocolate. I then experimented with the MapsMarker plugin in WordPress and tried to upload my data files to create new maps with different software. My markers failed to import time and time again, and I refused to make 1,498 new markers by hand; not only is that too costly in time, but it carries with it too much risk of human error. Trying to meet a deadline to share this map for a presentation at SHARP (it is the heart of this presentation), I purchased stainforth.org and activated it with godaddy’s third-party hosting, FTP’d my files there, and created the index file that would then publish the original Leaflet map. I then linked to that page from stainforth.scu.edu’s blog page.
On my to-do list for next year is to bend MapsMarker Pro to my will and successfully import my files to create markers that are part of The Stainforth Library of Women’s Writing DH site, not linked from another URL.
Stainforth Book Acquisitions
In the Winter, I collaborated with Nadia Nasr in Archives and Special Collections to purchase Early Efforts (1839), a Stainforth book by sisters Celia and Marion Moss. A private book dealer in NY contacted me via Instagram regarding the book sale; he found me through the Stainforth website. It is incredibly helpful for scholarship and pedagogy on the Stainforth project and on women’s book history to have a Stainforth book at SCU. I gave a presentation on this book at BWWC 2019, and also blogged about it for Arthur’s Attic, the Special Collections blog at SCU. I also researched and found two additional Stainforth books for sale on ebay. I bought Mary Maynard’s Shakespeare’s Dream or a Night in Fairy Land (1861) for my teaching collection – it was a bargain at $100. I also helped my co-editor in CU-Boulder Special Collections acquire Hannah Cowley’s play called The Fate of Sparta; or, The Rival Kings (1788) for their Women Poets in the Romantic Period collection, another book on ebay that I found with Stainforth’s bookplate. Collecting and cataloging these books where teachers and scholars can find them and access them is incredibly important for further research on Stainforth’s library and women’s book history.
Digital Book Hunt, 2018-19
This year, we made major changes to the Book Hunt component of The Stainforth Library website. This is the part of the project where we track and map where Stainforth’s original books are now in the world, and they are verifiable by his signature bookplate. The previous editor of the Book Hunt project left our editorial team in Spring 2018 to take a TT position as a Music professor in Memphis. In Fall 2019, I went through his documentation and files and determined that much needed to change. First, our previous map in CartoDB was connected to his personal Google account. This made it impossible for me to take ownership of the map. Luckily, the files that fed the CartoDB map were in our shared project team folder in Google Drive, so we were not at risk of losing data. I wanted to make mapping easier to update and share, so I moved it into Google My Maps, changed the marker icon to (cute) read books, and added a feature that allows a user to see the names of all the libraries on the map in a menu on the left side, and then to go to that library marker. This way, if a person is at a library and finds a Stainforth book, it’s easy to click on the library name where they are and determine if we already have that book mapped or if it’s an exciting new find.

In addition to upgrading our mapping platform, we also found 20 new Stainforth books this year, both in hardcopy and via digital scans that show the Stainforth bookplate. This brings our total to 321 original Stainforth books located. The British Library still holds the largest collection of them in the world. A small but important addition, I added a field to our book hunt submission form for a person’s email address so that we can reach back out to people who submit data on Stainforth books found — I was baffled when I realized the prior editor didn’t include this field.
New Page: See Also
https://stainforth.scu.edu/related-projects/
In August of 2018 and March of 2019, I was invited to participate in a women’s book history symposium with a group of scholars working on related projects. Many of these projects were DH projects and/or have DH components that are significant for women’s book history. We discussed our desire to start a Women’s Book History Network, and these discussions continue. In the meantime, we agreed that a first step to creating such a network is to acknowledge and link to associated digital scholarship. It is the least we can do. Along these lines, I added a new page to the project website called “See Also.” It will be a living list of related women’s book history projects and their links. At present, it links to the following projects:
- Aphra Behn Online (ABO): Interactive Journal for Women in the Arts, 1640-1830 http://scholarcommons.usf.edu/abo/
- Elizabeth Montague Correspondence Online
http://www.elizabethmontagunetwork.co.uk/emco/ - The Lady’s Magazine: Understanding the Emergence of a Genre https://www.kent.ac.uk/english/ladys-magazine/
- Novels Reviewed Database, 1790-1820
https://www.meganpeiser.com/novelsrevieweddatabase - Orlando: Women’s Writing in the British Isles from the Beginnings to the Present http://orlando.cambridge.org
- Reading with Austen https://www.readingwithausten.com
- RECIRC: The Reception and Circulation of Early Modern Women’s Writing, 1550-1700 http://www.recirc.nuigalway.ie
- Unpublished Manuscript Fiction in the Archive, 1750-1900 http://www.manuscriptfiction.org
- The Victoria Press Circle http://victoriapresscircle.org/
- Women in Book History Bibliography http://www.womensbookhistory.org/
- Women Writers Online https://www.wwp.northeastern.edu/wwo/
- The Women’s Print History Project, A Bibliography of Women’s Books, 1750-1836 https://womensprinthistoryproject.wordpress.com/
Blog Posts
In addition to editorial work, our team blogged a great deal about our findings and processes in order to perform public scholarship and share what we are learning. The list of blog posts includes:
- https://blogs.scu.edu/arthursattic/2019/07/03/using-provenance-to-trace-early-efforts-by-the-moss-sisters-in-19c-jewish-womens-book-history/
- The Grecians. A Tragedy, by Mrs. Vaughan (1824), with Stainforth bookplate;
- The Sisters Acton;
- Identify and Identity;
- Another woman of color;
- Adah Isaacs Menken;
- “Monument to Our Matrons,” short fiction inspired by the Stainforth library’s auction in 1867;
- Guest lecture @ SJSU, #bigger6 graduate seminar, with activities;
- Stainforth Projects by Danna D’Esopo and Leah Senatro at the 2019 DH Student Showcase;
- Sister co-authorship combined with cross-references = editorial pretzel
- And this blog post: The Stainforth Library, Project Development Recap 2018-19
Upcoming Year, 2019-20
Our goals for 2019-20 involve a lot of deep cleaning and shoring up our documentation before sending our project for peer review. This includes but is not limited to:
- fixing name duplicates
- encoding and publishing our cross-reference links
- updating our TEI header and schema, writing a custom TEI ODD
- adding a form to enable anyone to download our data from our homepage
- completing current editorial pass on all 1,066 Person records
- update Book Hunt map with recent book finds
- get publication place map into WP site via plugin (MapsMarkerPro, most likely)
- get caught up on fixing transcription errors found
- update published documentation of editorial practices and guidelines
- keep blogging our editorial processes
- submit for peer review in Summer 2020