The Stainforth Library of Women’s Writing project is hosted on the DH server at Santa Clara University and uses PHP for its source code. The project is conceptually divided into two parts: its core function as a scholarly digital edition of the catalog and the secondary projects that augment or make use of the data we have collected and edited. There is a public user interface and multiple private editorial interfaces. For an overview, see the accompanying slides “Technical Facets: The Stainforth Library of Women’s Writing.”


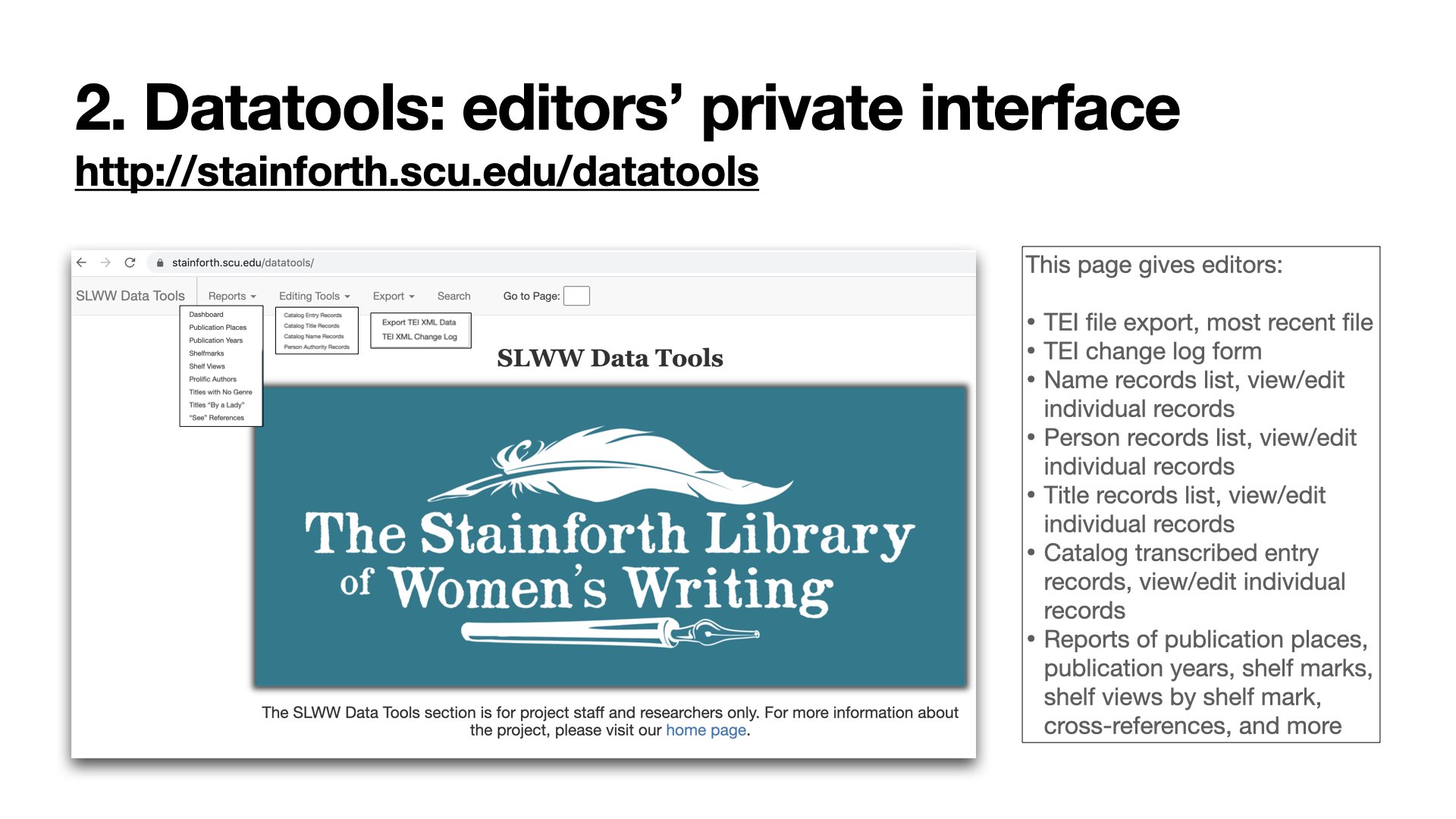
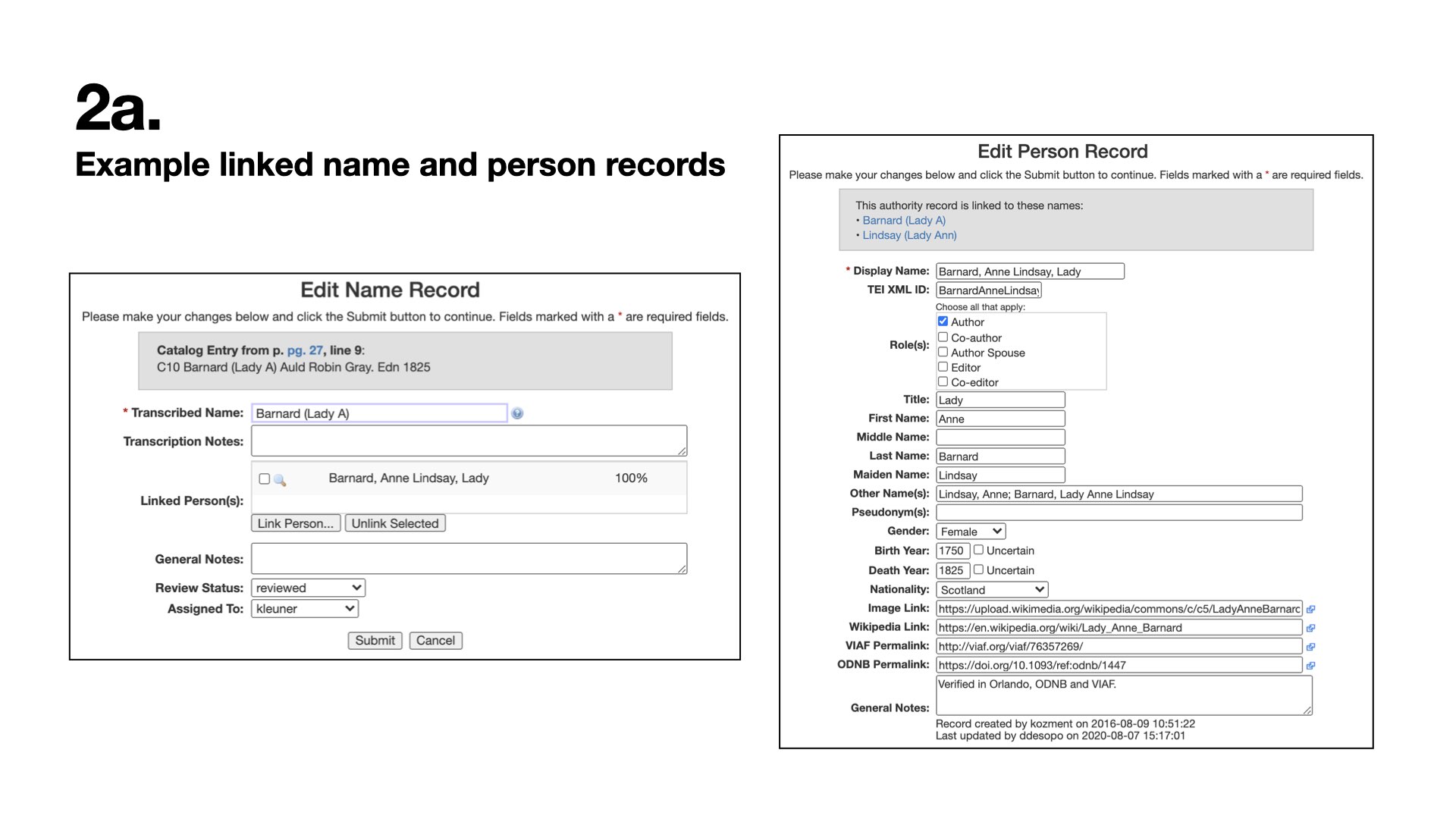
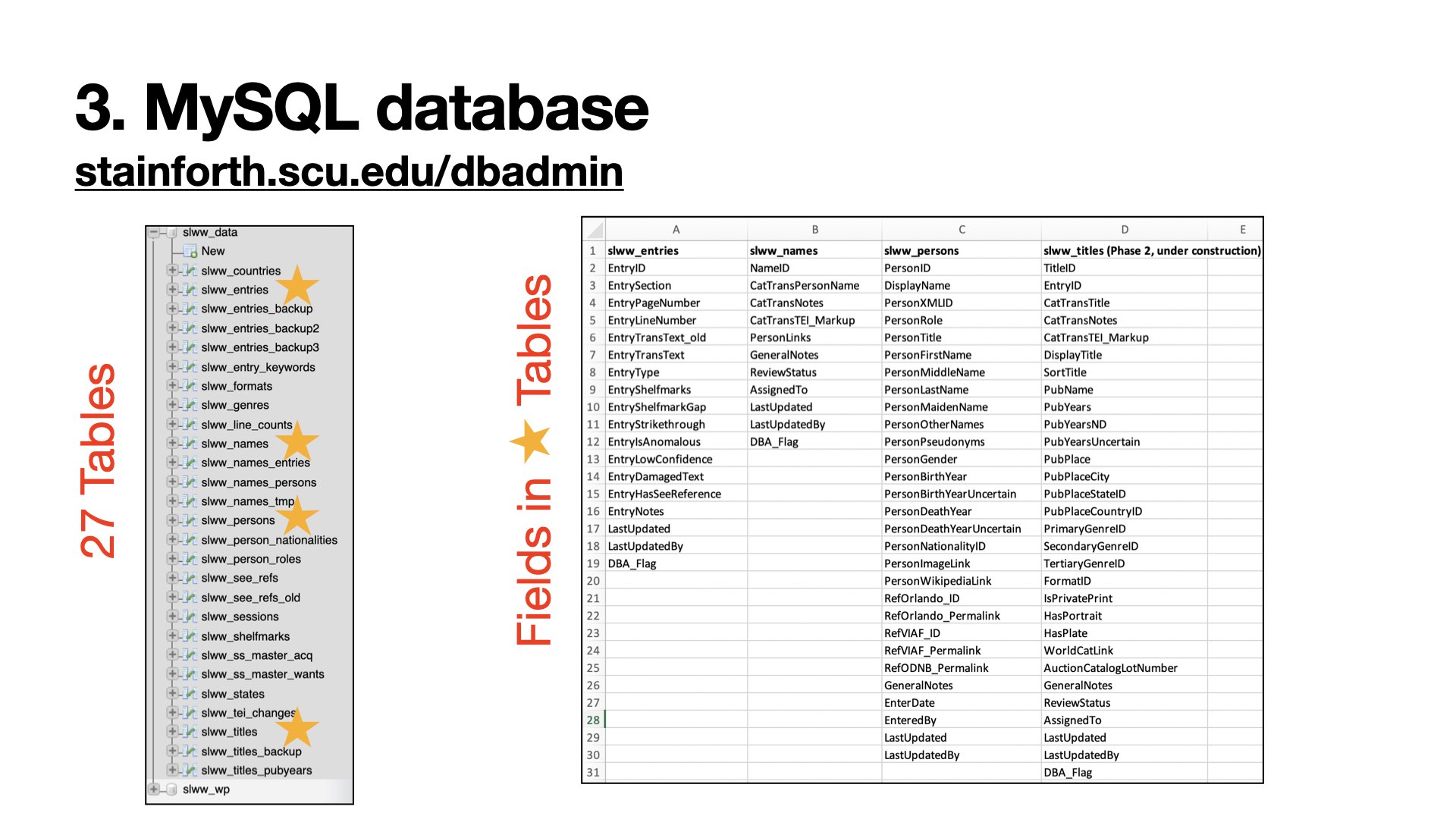


Work officially began on the digital edition in 2013. Editors transcribed each page of the 746-page catalog in shared Google Sheets, edited transcriptions, and lightly encoded them in XML following TEI P5 guidelines. Nearly all catalog entries follow a regular pattern of author, title, edition, publication place, and date, which allowed us to parse the transcribed lines into separate tables of a MySQL database. Editors access the data in two ways: (1) through a separate password-protected user interface of the CMS (WordPress site) called “Data Tools” that is designed specifically for editing person and title data, and (2) through phpMyAdmin, where an editor can query the full database in SQL. Only administrators have access to the full database.
As of August 2020, we have 27 tables of data. The database revolves around the Entries table, which has transcriptions of the catalog parsed by page and line number. Each entryID is connected to two tables where we have parsed transcribed names and titles, the latter of which also has bibliographic data such as publication place and year. Throughout these transcription tables, we maintained Stainforth’s spelling and presentation according to our editorial philosophy. We then use tertiary tables to provide verified information, which we call “editorial records,” that connect Stainforth’s transcriptions to identifiable books and people, making this data legible and usable elsewhere. Our largest Phase 1 editorial project has been the person records table. Other editorial tables track book formats, genres, line counts, cross references in the catalog, shelfmarks, a TEI change log, and keywords. We also have several backup tables of key data.
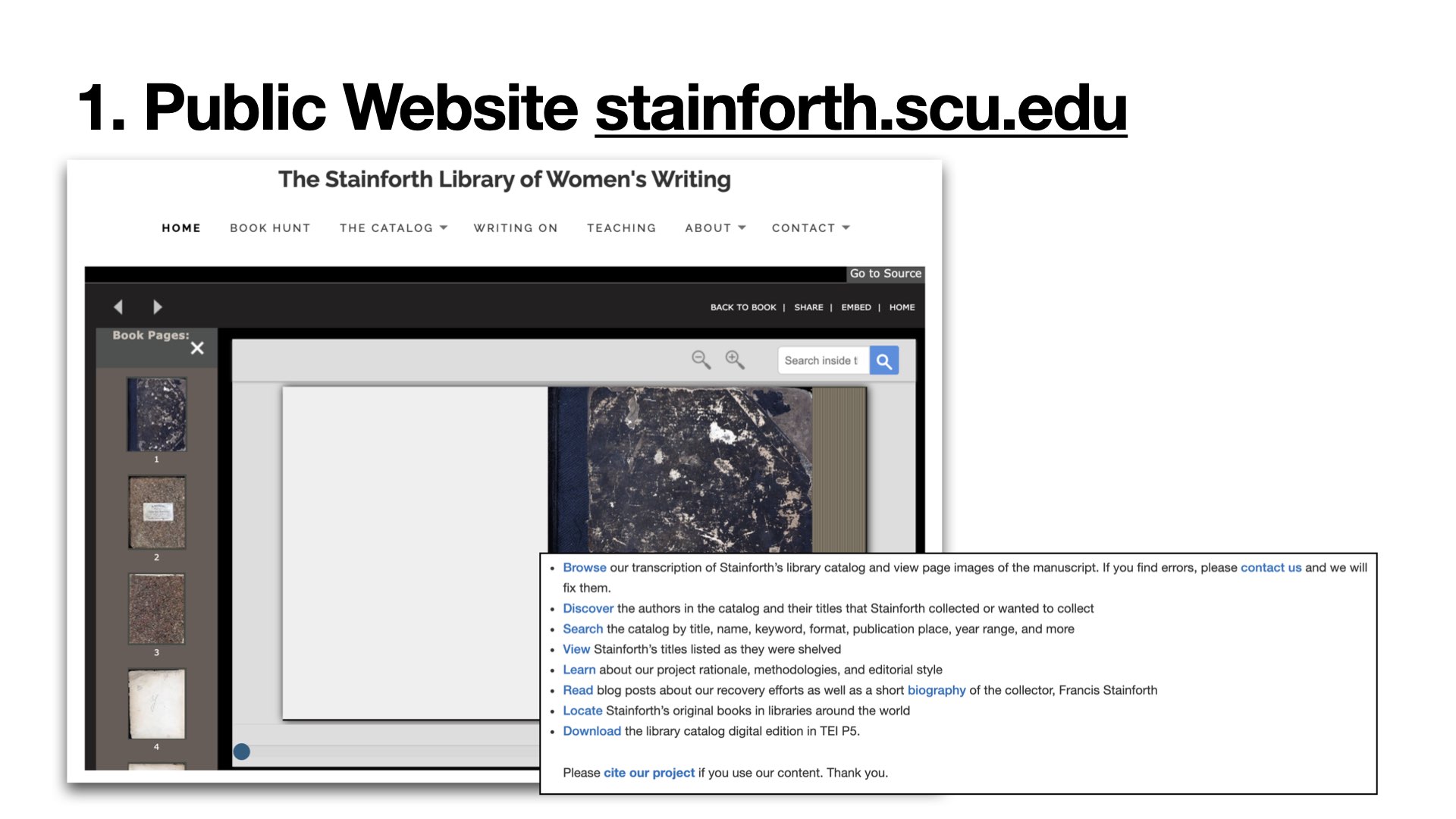
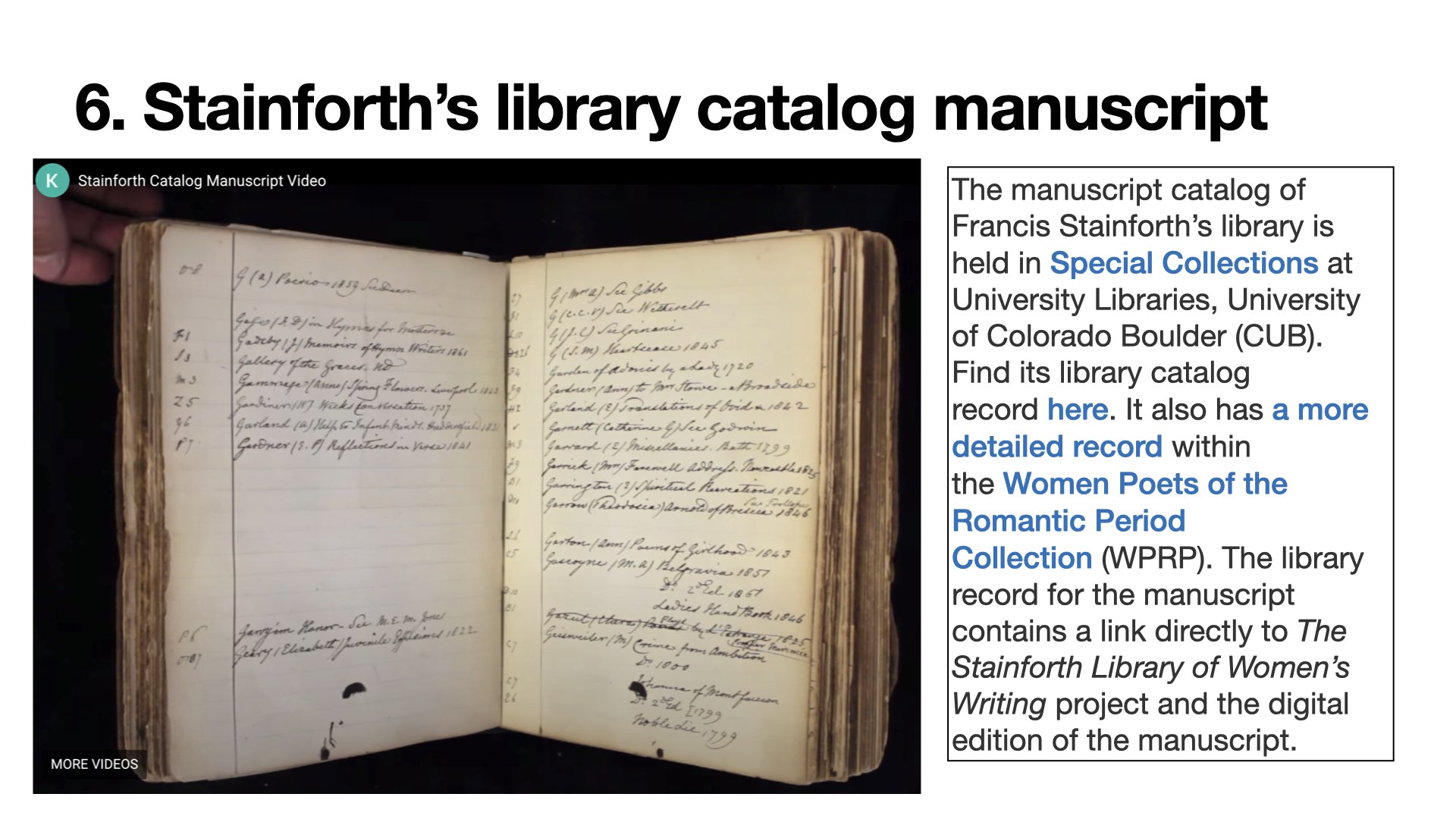
On the front end, users can conduct simple and advanced searches on the data in the catalog here: https://stainforth.scu.edu/catalog/search/. Our website uses the WordPress CMS to host the public-facing portion of the project. It is compliant with HTML5 and CSS3 standards and uses UTF-8 character encoding for textual data storage and presentation. A user can also browse the manuscript catalog to see what the pages look like in Stainforth’s hand by going here: https://stainforth.scu.edu/stainforths-library-catalog-transcription/. The site offers two browsing views of the manuscript. The first is an image of the manuscript page adjacent to its transcription to help a reader interpret Stainforth’s hand. Below this, there is an embedded “flippable” full-page spread view of the manuscript in LUNA, hosted at CU Boulder University Libraries. Under a Creative Commons Attribution -Non-Commercial-Share Alike 4.0 license, anyone can request and receive a copy of our TEI encoded XML data at any point. This form on our site allows users to directly request data downloads. Right now, the TEI download is the only way to full-text-search the entire catalog or search person records on the user end.
There are several components of the project that supplement the searchable digital library catalog and support analysis of the catalog. These include:
- 2,818 person records (like this one for Cecil Frances Alexander) that describe the names Stainforth recorded in his catalog and link those we can identify to Name Authority records in the Virtual International Authority File (VIAF). For authors in the catalog who do not have a Name Authority record, we collaborate with NACO-certified librarians to create such a Library of Congress record, which also adds it to VIAF. Name Authority records are important because they make authors findable in library catalogs. Currently person records, editorial records created to describe the names mentioned in the catalog, are best searched in our downloadable TEI file.
- Google Map of ~300 of Stainforth’s original books found around the world, identifiable by their bookplate. See what we’ve found here: https://stainforth.scu.edu/mapping-stainforths-books/. Librarians, bookdealers, and collectors continue to contact our project via this form to tell us about their Stainforth books, and Stainforth project editors continue to locate books we haven’t mapped yet. All data is kept in Google Sheets, which only editors access. Only ~7,000 more books to find.
- Leaflet map of all publication cities in Stainforth’s library catalog. Users can tailor the date range to a literary era or a custom range. The map is helpful for identifying regional clusters of publishers who produced women’s writing. Note that publishers in the same city that have different street addresses share the same marker location in this draft of the map. See https://stainforth.scu.edu/map-of-publication-places-in-the-library-catalog/ to explore the map.
- Project editors and student research assistants have been publishing on The Stainforth Library’s blog since 2014. It is a record of the project’s development and an outlet for publishing findings and updates that are important to share quickly.
- The Stainforth Library lends itself to pedagogy in multiple disciplines. We have published a collection of lesson plans for a range of assignments from short classroom activities to term-long projects. They are free to adapt as needed. See https://stainforth.scu.edu/teaching/ for more information.
- Find documentation of our editorial processes here: https://stainforth.scu.edu/about/. We have also published a short biography of the collector, Francis Stainforth.
- Our “See Also” page refers visitors to DH projects that are related to Stainforth https://stainforth.scu.edu/related-projects/